
Từ khả năng trò chuyện thông minh như người thật của các mô hình ngôn ngữ lớn, cho đến năng lực tự nhận diện chướng ngại vật của xe tự lái, tất cả các phép màu công nghệ hot nhất hiện nay thực chất đều được vận hành bởi một công nghệ chung. Chính là chìa khóa mở ra kỷ nguyên nhận diện siêu việt mà con người từng nghĩ chỉ có trên phim viễn tưởng. Bài viết này, Maytinhdohoa sẽ giải thích toàn bộ khái niệm kỹ thuật phức tạp này thành thông tin dễ hiểu nhất dành cho người mới bắt đầu.

I. định nghĩa Deep Learning là gì?
Deep Learning là một tập hợp con chuyên sâu thuộc Học máy (Machine Learning), hoạt động dựa trên cấu trúc các mạng nơ-ron nhân tạo nhiều tầng lớp. Kỹ thuật này cho phép máy tính tự động tiếp thu kiến trúc dữ liệu phi cấu trúc khổng lồ, tự khai phá các đặc trưng ẩn mà không cần đến sự định hướng hay dán nhãn thủ công từ con người.
1. Deep Learning và Machine Learning khác nhau thế nào?
Điểm khác biệt cốt lõi nằm ở cách thức xử lý dữ liệu và mức độ can thiệp của con người. Đối với Machine Learning truyền thống, nếu muốn máy nhận diện một chiếc ô tô, kỹ sư bắt buộc phải lập trình thủ công các thuộc tính đặc điểm đặc trưng như: có 4 bánh, có vô lăng, có đèn pha.
Trong khi đó, với Deep Learning, bạn chỉ cần nạp thẳng hàng triệu bức ảnh thô vào hệ thống. Thuật toán học sâu sẽ tự động phân lớp, tự nhận biết các đường nét góc cạnh để đưa ra kết luận phân loại mà không cần bất kỳ sự hướng dẫn nào từ lập trình viên.
II. Mạng nơ-ron nhân tạo – Nền tảng của Học sâu
Để mô phỏng lại năng lực tư duy của bộ não con người, cấu trúc phần mềm của Deep Learning sử dụng mạng lưới nơ-ron nhân tạo (Artificial Neural Network – ANN) được bện chặt bởi các thành phần chính:
1. Cấu trúc Layer, Node và Trọng số
- Node (Điểm nút): Đóng vai trò như một tế bào nơ-ron thần kinh, chịu trách nhiệm nhận tín hiệu đầu vào, thực hiện phép tính toán và truyền tín hiệu đầu ra.
- Layer (Tầng lớp): Tập hợp các Node song song. Một mạng lưới cơ bản gồm Tầng đầu vào (Input Layer), các Tầng ẩn (Hidden Layers) và Tầng đầu ra (Output Layer).
- Trọng số (Weight): Thể hiện mức độ quan trọng của kết nối giữa các Node. Trong quá trình học, máy sẽ liên tục điều chỉnh các hệ số này để giảm thiểu sai số dự đoán.
2. Tại sao lại gọi là “Deep”?
Từ “sâu” ở đây dùng để mô tả quy mô kiến trúc của các Hidden Layers. Một mạng lưới nơ-ron thông thường chỉ có từ 1 đến 2 tầng ẩn. Tuy nhiên, một mô hình Deep Learning hiện đại sở hữu cấu trúc xếp chồng lên tới hàng chục, hàng trăm, thậm chí hàng ngàn lớp nơ-ron đan xen. Chính độ sâu này giúp máy bóc tách được các tầng ý nghĩa trừu tượng nhất của dữ liệu thô.
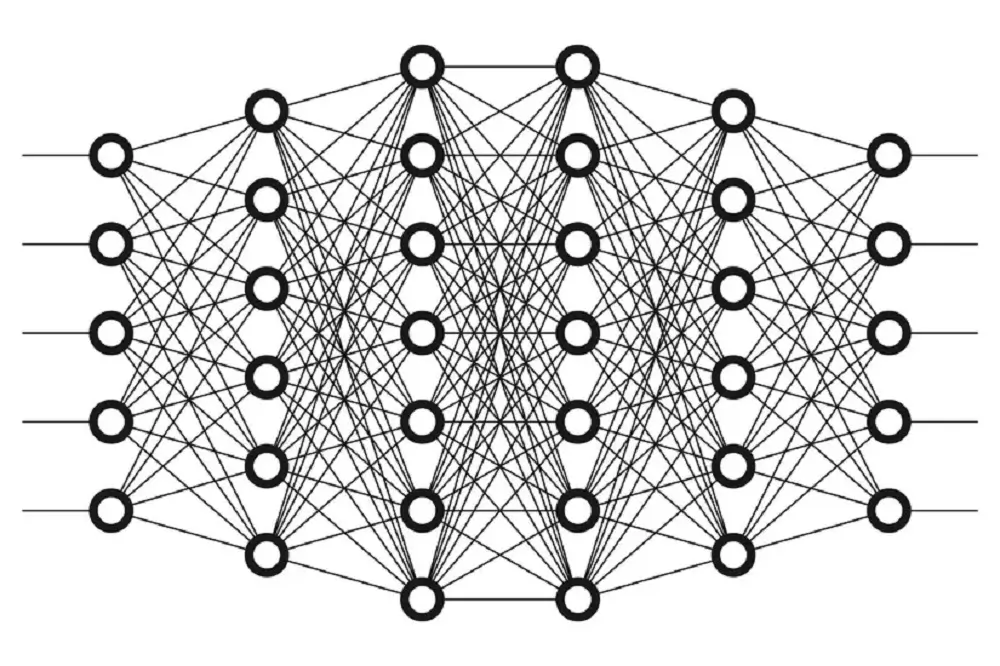
III. Ví dụ trực quan về cách thức vận hành của Deep Learning
Hãy hình dung bài toán dạy máy tính nhận diện một con mèo qua một triệu tấm ảnh thô không gán nhãn:
- Tầng ẩn đầu tiên: Máy quét bề mặt và chỉ nhận diện được các dải pixel độ tương phản, các đường nét hình học thẳng, cong cơ bản nhất.
- Tầng ẩn tiếp theo: Kết hợp các đường nét để nhận biết các khối cấu trúc phức tạp hơn như hình dáng tai tam giác, râu mèo, hốc mắt.
- Tầng ẩn sâu nhất: Tổng hợp toàn bộ các khối hình học để định hình nên chân dung hoàn chỉnh của con mèo và đưa ra kết quả xác suất ở tầng đầu ra.
Toàn bộ chu kỳ này lặp đi lặp lại hàng triệu lần, mô hình tự động sửa sai qua các thuật toán lan truyền ngược (Backpropagation) cho đến khi đạt độ chính xác kịch trần.
IV. Lịch sử phát triển: Từ ý tưởng sơ khởi đến sự bùng nổ của phần cứng
Ý tưởng về mạng nơ-ron nhân tạo đã được nhen nhóm từ những năm 1960. Tuy nhiên, ở thời điểm đó, công nghệ học sâu nhanh chóng rơi vào ngõ cụt và bị bỏ quên suốt nhiều thập kỷ do hai rào cản vật lý: hạ tầng tính toán của CPU thời bấy giờ quá yếu và nguồn dữ liệu số hóa trên thế giới quá khan hiếm. Phải bước sang kỷ nguyên bùng nổ Internet (Big Data) kết hợp cùng kiến trúc tính toán song song song hành của chip đồ họa GPU, Deep Learning mới thực sự được giải phóng hỏa lực để thống trị thế giới công nghệ như ngày nay.
V. Các ứng dụng thực tiễn thay đổi thế giới của Deep Learning
- Thị giác máy tính (Computer Vision): Ứng dụng xuất sắc trong hệ thống quét nhận diện khuôn mặt bảo mật, tự động phân tích hình ảnh y tế (chụp X-quang, MRI) để tầm soát tế bào ung thư sớm với độ chính xác vượt trội hơn cả bác sĩ chuyên khoa.
- Xử lý ngôn ngữ tự nhiên (NLP): Nền tảng cốt lõi để xây dựng các trợ lý ảo, chatbot thông minh, phần mềm dịch thuật đa ngôn ngữ ngữ cảnh thời gian thực phẳng mượt.
- Công nghệ xe tự lái: Xử lý hàng chục luồng video camera trực tiếp truyền về theo thời gian thực, giúp hệ thống tự động đưa ra quyết định phanh, rẽ, tránh chướng ngại vật an toàn tuyệt đối.
VI. Đánh giá ưu điểm và nhược điểm của công nghệ học sâu
| Ưu điểm đột phá | Nhược điểm & Hạn chế |
|---|---|
| – Đạt hiệu suất xử lý cực đỉnh đối với các khối dữ liệu khổng lồ. – Tự động khai phá các đặc trưng ẩn, không cần con người lọc dữ liệu. – Khả năng tự học và thích nghi tối ưu với nhiều dạng bài toán đa ngành. |
– Đòi hỏi nguồn dữ liệu huấn luyện đầu vào khổng lồ kịch khung. – Mô hình “Hộp đen” (Black Box) rất khó giải thích quy trình đưa ra quyết định logic bên trong. – Yêu cầu hạ tầng linh kiện phần cứng máy trạm vô cùng đắt đỏ. |
VII. Huấn luyện (Train) Deep Learning bắt buộc cần cấu hình phần cứng gì?
Quá trình nạp hàng triệu tham số toán học của mạng nơ-ron là một bài toán tra tấn phần cứng khủng khiếp. Kiến trúc của các dòng chip CPU thông thường dù có cao cấp đến mấy cũng chỉ sở hữu số nhân đếm trên đầu ngón tay, được tối ưu cho việc xử lý tuần tự nên hoàn toàn bất lực trước ma trận học sâu, trực tiếp gây vỡ mạch và sập tiến trình hệ thống.
Để giải quyết bài toán này, hạ tầng bắt buộc phải dựa vào sức mạnh tính toán song song của hệ thống Card VGA chuyên dụng trạm đồ họa chuyên nghiệp sở hữu hệ thống nhân Tensor Core đặc chủng kết hợp dung lượng bộ nhớ VRAM lớn (tối thiểu từ 16GB, 24GB trở lên). Đầu tư lắp ráp một hệ thống máy chạy trí tuệ nhân tạo cấu hình cao ngay tại chỗ là phương án tài chính tối ưu nhất giúp các kỹ sư, phòng Lab làm chủ hoàn toàn tốc độ xử lý dữ liệu, render mô hình phẳng tru trường kỳ mà không chịu chi phí vận hành đắt đỏ của cloud.
VIII. Giải đáp các câu hỏi thường gặp (FAQ) về Deep Learning
1. Học sâu Deep Learning và Trí tuệ nhân tạo AI khác nhau thế nào?
AI là khái niệm bao quát toàn bộ máy móc thông minh. Học máy Machine Learning nằm trong AI, và Học sâu Deep Learning chính là lõi kỹ thuật cao cấp nhất nằm sâu bên trong Học máy.
2. Muốn dấn thân nghiên cứu Deep Learning cần chuẩn bị gì trước?
Bạn bắt buộc phải thành thạo ngôn ngữ lập trình Python, có nền tảng toán học đại số tuyến tính vững chãi và làm chủ hai bộ framework thư viện mã nguồn mở sừng sỏ là PyTorch hoặc TensorFlow.
3. Chạy thuật toán học sâu có bắt buộc phải dùng GPU của NVIDIA không?
Về mặt kỹ thuật là có ở phân khúc chuyên nghiệp. Nhờ hệ sinh thái kiến trúc mã lập trình CUDA độc quyền được bện chặt và tối ưu hóa hoàn hảo với toàn bộ các thư viện AI trên toàn thế giới, GPU NVIDIA hiện là lựa chọn phần cứng tối ưu duy nhất bảo chứng cho quy trình train model diễn ra mượt mà.
IX. Kết luận
Deep Learning chính là động cơ phản lực đứng sau sự bứt phá thần kỳ của trí tuệ nhân tạo trong kỷ nguyên số. Việc đầu tư và làm chủ nền tảng này sẽ mở ra dải cơ hội phát triển đột phá cho mọi doanh nghiệp và nhà phát triển phần mềm.
Hệ thống showroom công nghệ Maytinhdohoa tự hào là đơn vị uy tín hàng đầu cung cấp giải pháp máy trạm Workstation AI chuyên dụng chính hãng. Hãy liên hệ với chúng tôi ngay hôm nay để nhận tư vấn cấu hình phần cứng tối ưu nhất cho bài toán dự án của bạn nhé!








